python基础学习
python基础
注释
python中单行注释以#开头,多行注释可以用多个#号,或者采用'''和"""
行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 { }
字符串
python中单引号和双引号使用完全相同。
使用三引号(‘’’或”””)可以指定一个多行字符串。
转义符 ‘'
反斜杠可以用来转义,使用r可以让反斜杠不发生转义。。 如 r”this is a line with \n” 则\n会显示,并不是换行。这里的r指raw,即raw string原始字符串
按字面意义级联字符串,如”this “ “is “ “string”会被自动转换为this is string。
字符串可以用 + 运算符连接在一起,用 * 运算符重复。
Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
Python中的字符串不能改变。
Python 没有单独的字符类型,都为字符串,一个字符就是长度为 1 的字符串。
字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
等待用户输入

print输出
print默认输出是换行的,如果想要不换行需要在变量末尾加上end=” “
import与from…import
在 python 用import或者from...import来导入相应的模块。
将整个模块(somemodule)导入,格式为:import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为:from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
python基本数据类型
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的”类型”是变量所指的内存中对象的类型。
标准数据类型
python3中有6个标准的数据类型
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Number(数字)
支持int,float,bool,complex(复数)
其中内置的type()函数可以用来查询变量所指的对象类型。
数值运算:
1 | 5 + 4 # 加法 |
需要注意:一个变量可以通过赋值指向不同类型的对象,数值的除法包含两个运算符:/返回一个浮点数,//返回一个整数。
String(字符串)
字符串或串(String)是由数字、字母、下划线组成的一串字符。
Python中的字符串用单引号'或双引号"括起来,同时使用反斜杠\转义特殊字符。
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
逆序输出字符串:
从字符串中截取一串字符:使用 [头下标:尾下标] 来截取相应的字符串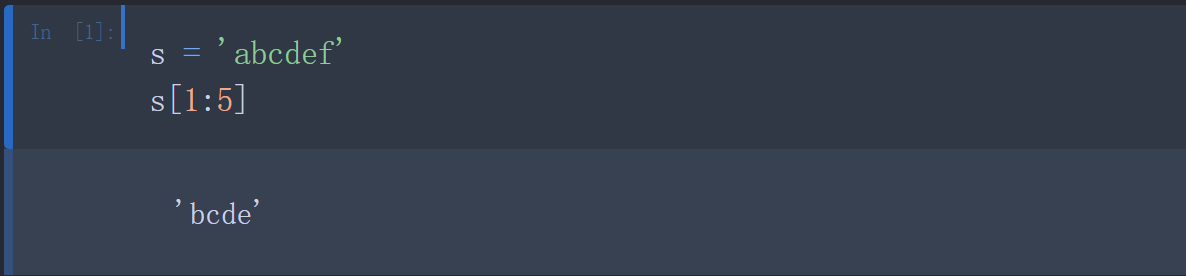
[头下标:尾下标]获取的子字符串包含头下标的字符,但不包含尾下标的字符。
List列表
List(列表) 是 Python 中使用最频繁的数据类型。
list是一种有序的集合,可以随时添加和删除其中的元素。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。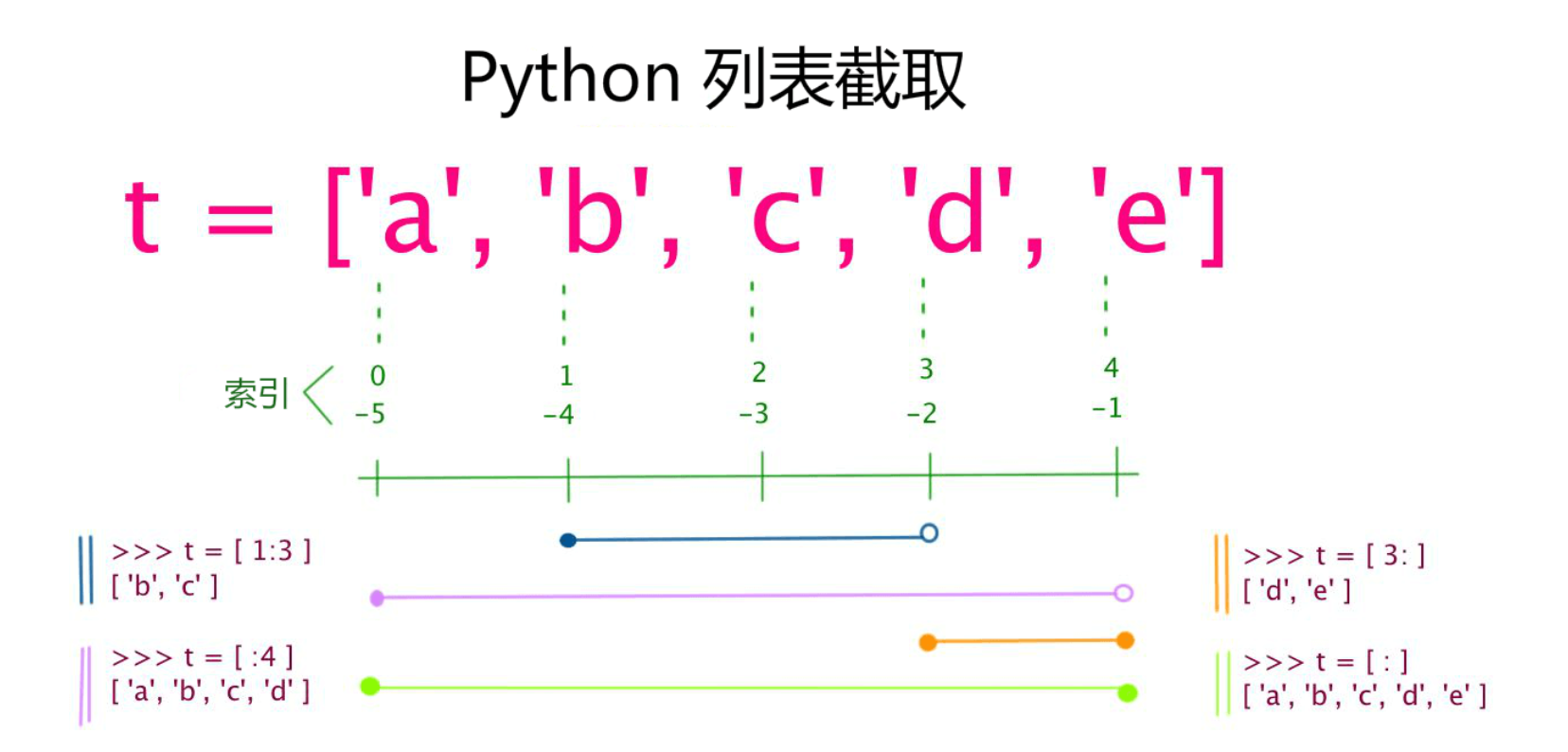
list是一个可变的有序表,所以,可以往list中追加元素到末尾: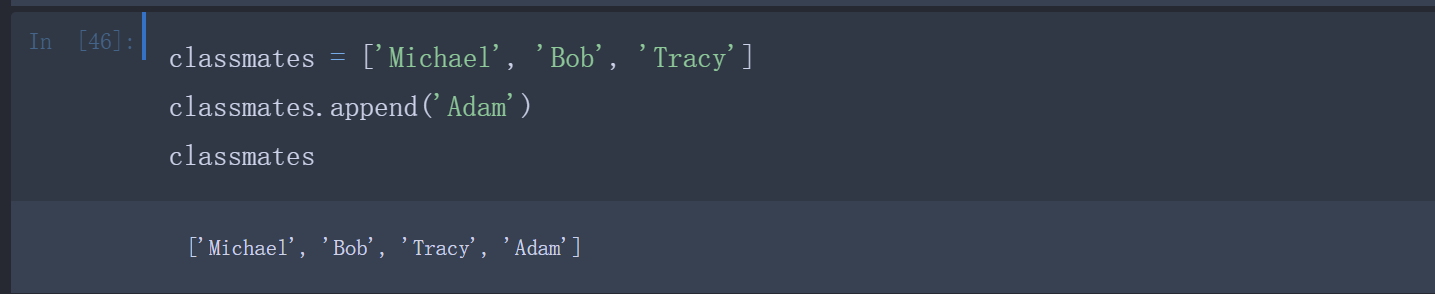
也可以把元素插入到指定的位置,比如索引号为1的位置:
要删除list末尾的元素,用pop()方法:
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
元组
元组类似于列表(list,不同之处在于元组的元素不能修改。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
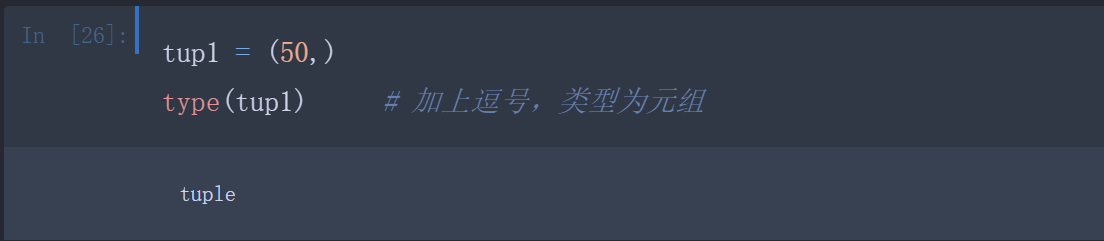
当元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用: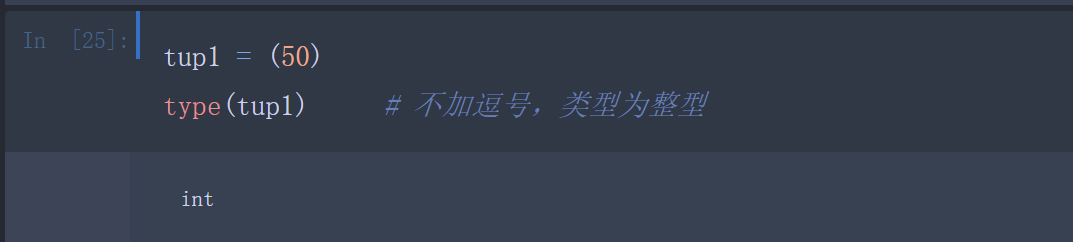 )
)
元组内置函数:
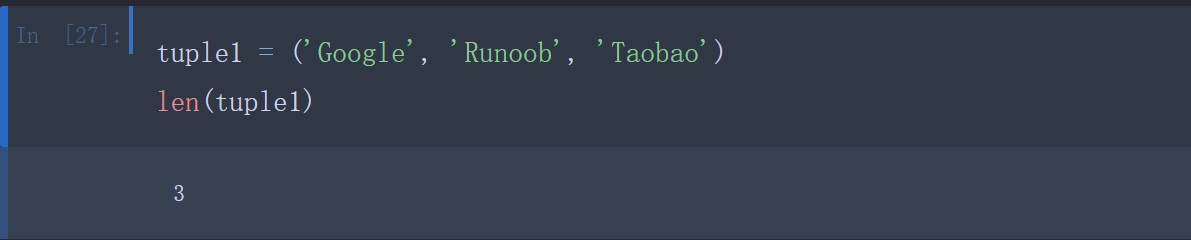
- len(tuple):计算元组元素个数。
- max(tuple):返回元组中元素最大值。

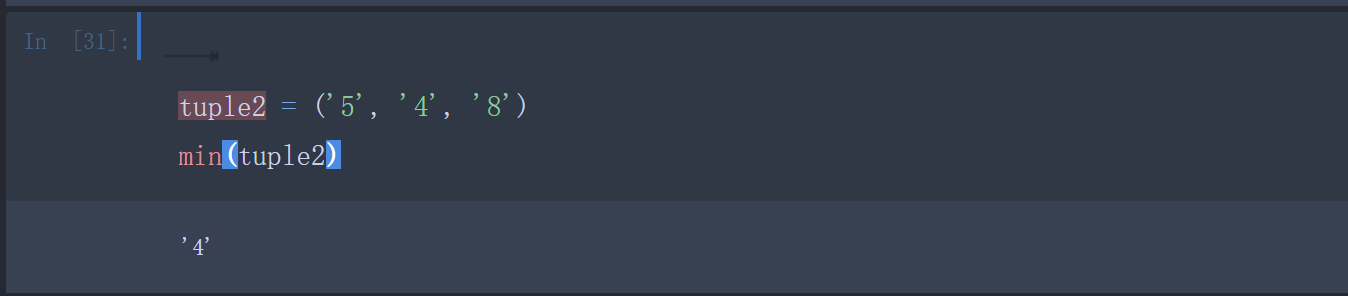
- min(tuple):返回元组中元素最小值。
- tuple(iterable) 将可迭代系列转换为元组。

字典
字典是另一种可变容器模型,且可存储任意类型对象。
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
给定一个名字,要查找对应的成绩。用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下
注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 1、查找和插入的速度极快,不会随着key的增加而变慢;
- 2、需要占用大量的内存,内存浪费多。
所以,dict是用空间来换取时间的一种方法。dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
重复的元素在set中会被自动过滤:
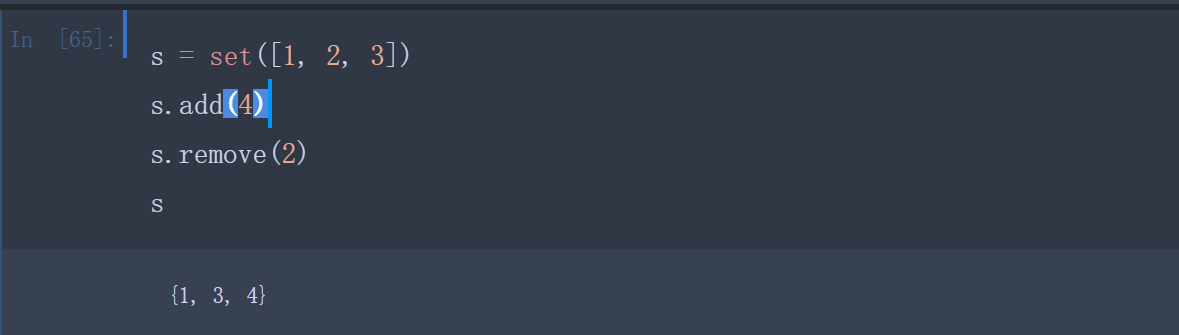
通过add(key)方法可以添加元素到set中,通过remove(key)方法可以删除元素: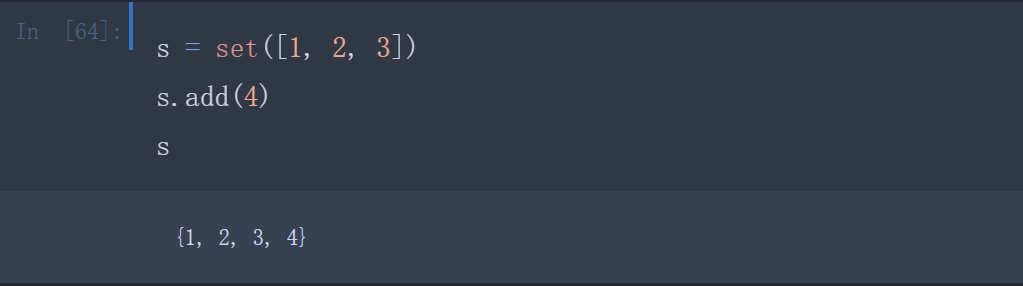 )
)
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。
计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件: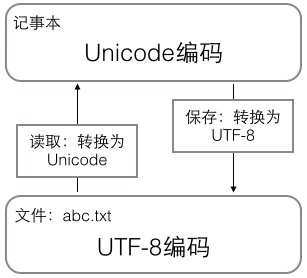
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器: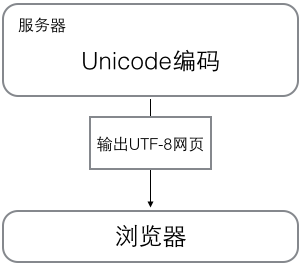
所以当看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python 3的字符串使用Unicode,直接支持多语言。
当str和bytes互相转换时,需要指定编码。最常用的编码是UTF-8
要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
谈谈input
很多时候我们会用input()读取用户的输入,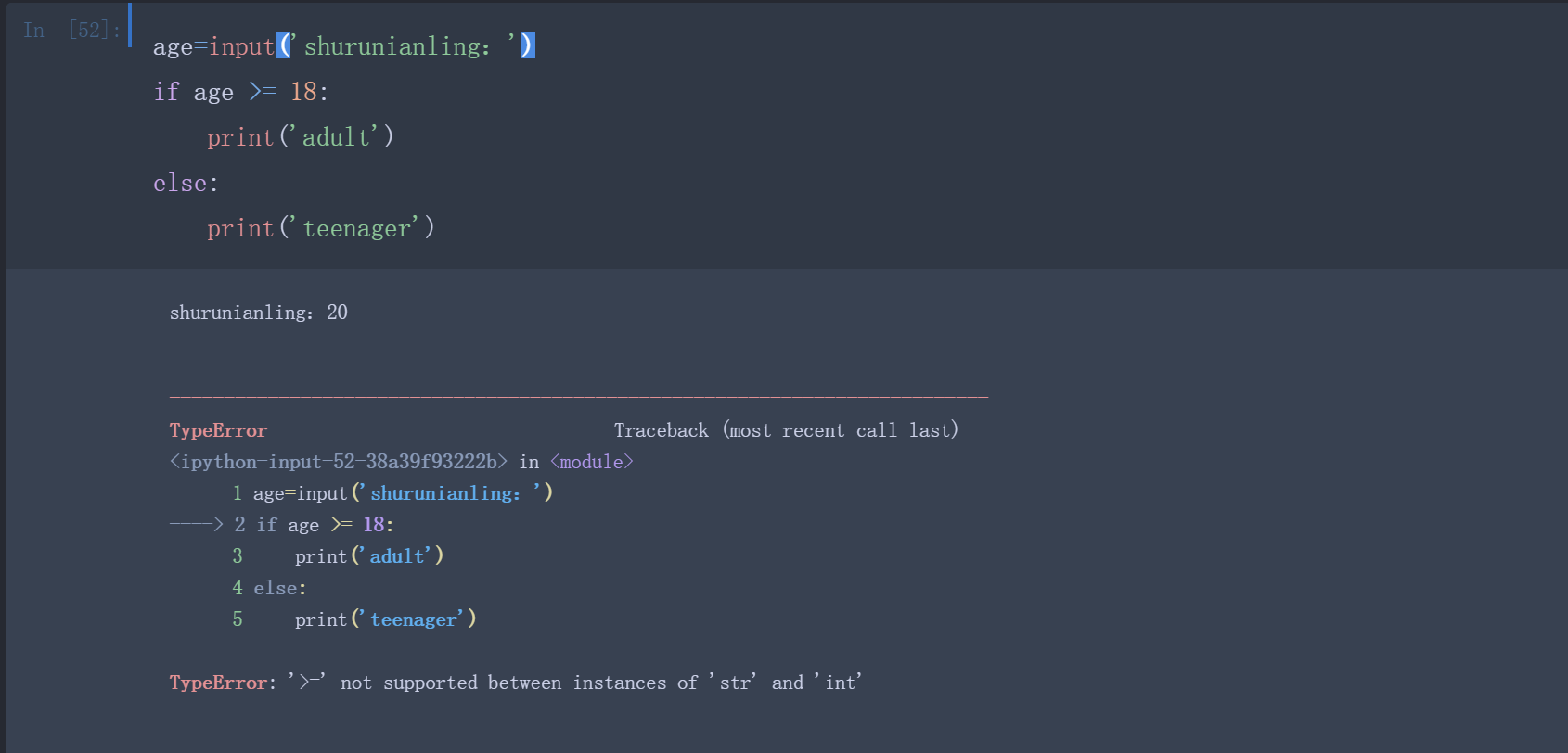
结果报错,这是因为input()返回的数据类型是str,str不能直接和整数比较,必须先把str转换成整数。Python提供了int()函数来完成这件事情: