python安装dlib遇到的错误:AttributeError:module ‘dlib’ has no attribute ‘get_frontal_face_detector’问题解决
dlib是一个非常好用的跨平台的通用库,但是在安装过程中遇到了许多问题,我在使用Anaconda安装dlib过程中,用pip install 安装,安装成功后,import没有问题
dlib是一个非常好用的跨平台的通用库,但是在安装过程中遇到了许多问题,我在使用Anaconda安装dlib过程中,用pip install 安装,安装成功后,import没有问题
vector是线性容器,可叫做“变长数组”,即“长度可根据需要而自动改变的数组”调整存储空间大小。它的元素存储在一块连续的存储空间中,可以使用迭代器iterator和指针的偏移地址访问元素。
单独定义一个vector:vector<typename> name;
这个定义相当于是一维数组name[SIZE],不过长度可以根据需要进行变化,比较节省空间。
typename可以是任何基本类型,例如int,double、char、结构体等,也可以是STL标准容器,例如vector、set、queue等。
如果typename是vector,可以按下面这样定义:vector<vector<int> > name;
(1)通过下标访问
和访问普通数组是一样,对一个定义为vector
(2)通过迭代器访问
迭代器(iterator)定义:vector<typename>::iterator it;
可以将迭代器理解为一种类似指针的东西。
可通过类似下表和指针访问数组的方式来访问容器内的元素:
1 |
|
vec[i]和*(vec.begin()+i)是等价的。
vector的特点如下:string的定义
定义string的方式跟基本数据类型相同,只需要在stirng后面跟上变量名,string str;,初始化可以海子街给string类型的变量赋值。string str="abcd";
string中内容的访问:
(1)可以直接通过下标访问,str[i]
(2)通过迭代器访问,string::iterator it;
1 |
|
string和vector一样,可以直接对迭代器进行加减某个数字,如str.begin()+3
常用函数实例
两个string可以直接通过+拼接起来。
两个string类型可以直接使用==、!=、<、<=、>、>=比较大小,比较规则是字典序。(比较两个字符串对应的ASCII码值)
length()/size(),length()返回string的长度,即存放的字符数,时间复杂度为O(1)。
insert()
erase()
两种用法:删除单个元素,删除一个区间内的所有元素。
str.erase(it)用于删除单个元素,it为需要删除的元素的迭代器。
1 | string str:生成空字符串 |
1 |
|
输出结果:
- size()和length():返回string对象的字符个数,它们执行效果相同。
- max_size():返回string对象最多包含的字符数,超出会抛出length_error异常
- capacity():重新分配内存之前,string对象能包含的最大字符数
方法一:使用C语言的函数,进行转换
1 |
|
1 |
|
结果:
pi is 3.141593
28 is a perfect number
set,是一个内部自动有序且不含重复元素的容器。set作为一个容器是用来存储同一数据类型的数据类型,并且能从一个数据结合中取出数据,在set中每个元素的值都是唯一的,
set常用函数实例
1.insert(x)
可将x插入set容器中,并自动递增排序和去重,时间复杂度为O(logN),其中N为set内的元素个数。
2.find()
find(value)返回set中对应值为value的迭代器,时间复杂度为O(logN),N为set内的元素个数。
3.erase()
1 |
|
1 |
|
4.size()
用来获取set内元素的个数,时间复杂度为O(1)。
5. clear()
清空set内的所有元素,复杂度为O(N),其中N为set内元素的个数
map本质是一个关联式容器,它提供一对一的hash。里面的数据都是成对出现的:
map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。map主要用于资料一对一映射(one-to-one)的情況,map內部的实现自建一颗红黑树(一种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能。在map内部所有的数据都是有序的,后边我们会见识到有序的好处。1.插入元素
map的插入有3种方式:用insert函数插入pair数据,用insert函数插入value_type数据和用数组方式插入数据。
第一种:用insert函数插入pair数据
1 | map<int, string> mapStudent; |
第二种:用insert函数插入value_type数据
1 | map<int, string> mapStudent; |
用make_pair
1 | mapStudent.insert(make_pair(1, "student_one")); |
第三种:用数组方式插入数据
1 | map<int, string> mapStudent; |
以上四种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能再插入这个数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对应的值,即:如果当前存在该关键字,则覆盖改关键字的值,否则,以改关键字新建一个key—value;
2.查找元素
用find函数来定位数据出现位置,它返回的一个迭代器,当所查找的关键字key出现时,它返回数据所在对象的位置,如果沒有,返回迭代器等于end函数返回的迭代器。
1 | // find 返回迭代器指向当前查找元素的位置否则返回map::end()位置 |
3.删除与清空元素
1 | //迭代器刪除 |
4.map的大小
在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:int nSize = mapStudent.size();
5.map的基本操作函数
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
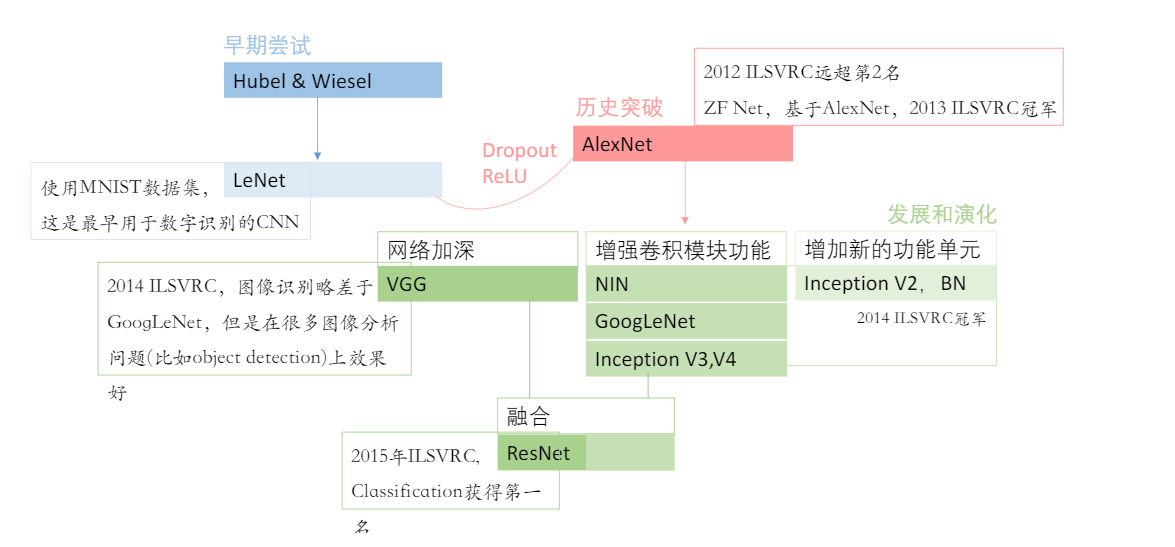
全连接神经网络DNN由于模型结构不够灵活,模型参数太多,通过模型改进,就出现了卷积神经网络CNN。
CNN在结构上有三大特性:
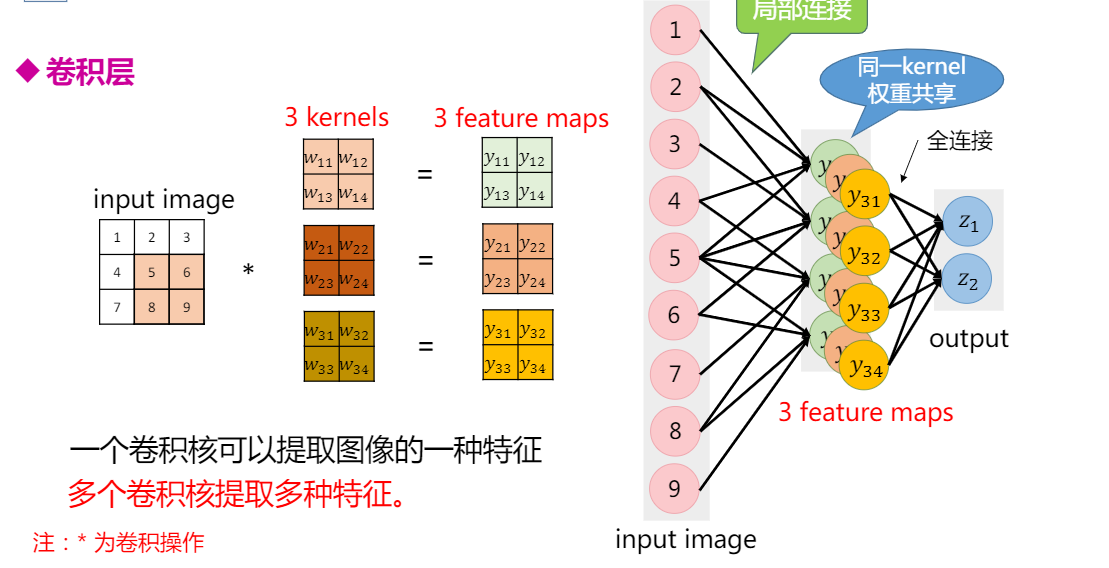
局部连接,在我们进行图像识别的时候,不需要对整个图像进行处理,只需要关注图像中某些特殊的区域,一张640x480的图片,可能其中的16x16个像素
权重共享
下采样,减小图片的尺寸,
可以减少网络参数,加快训练速度。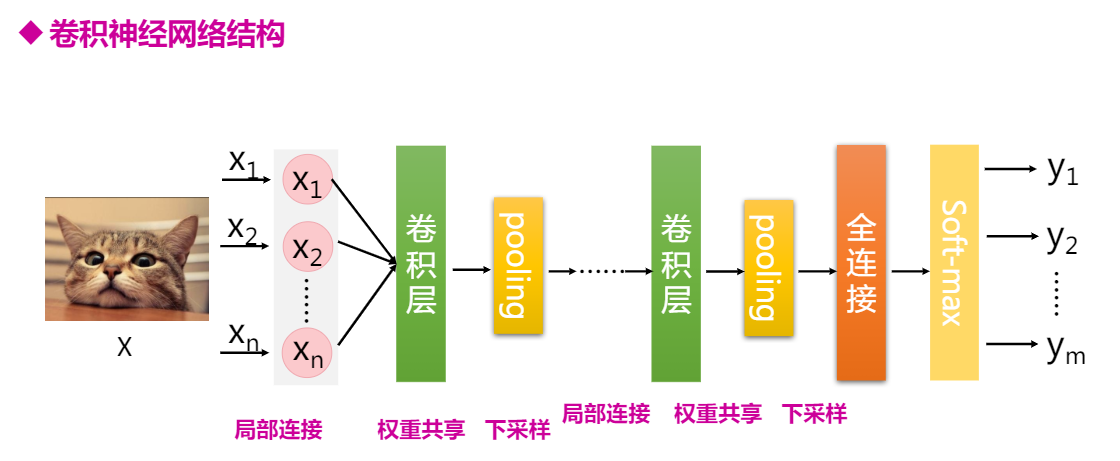 )
)
Pooling 池化层
通过下采样缩减feature map尺度。常用maxpooling和averagepooling.
这几天参加了百度飞桨举办的深度学习7日入门-CV疫情特辑课程,通过几个疫情AI实战案例,轻松入门深度学习。
利用python爬取丁香园公开的统计数据,根据累计确诊数,使用pyecharts绘制疫情分布图,通过查阅Pycharts api比较容易实现
1 | import json |
结果图: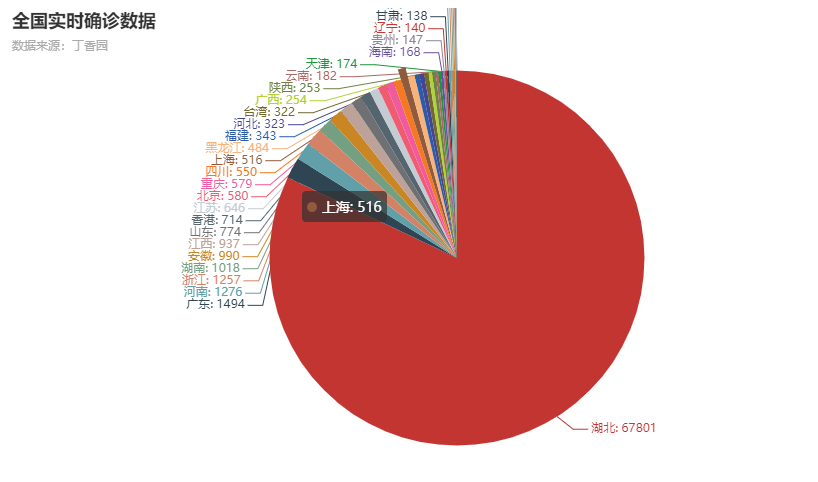
属于图像分类任务,根据图像的语义信息将不同类别图像区分开,是计算机视觉中重要的基本问题。手势识别属于图像分类中的一个细分类问题。
主要步骤:
1 | #定义DNN网络 |
其中通过查看Paddle API,更改了几种不同的优化器和模型参数,最终accuracy还是达不到90%,还是不太会该如何选取参数。
识别结果:
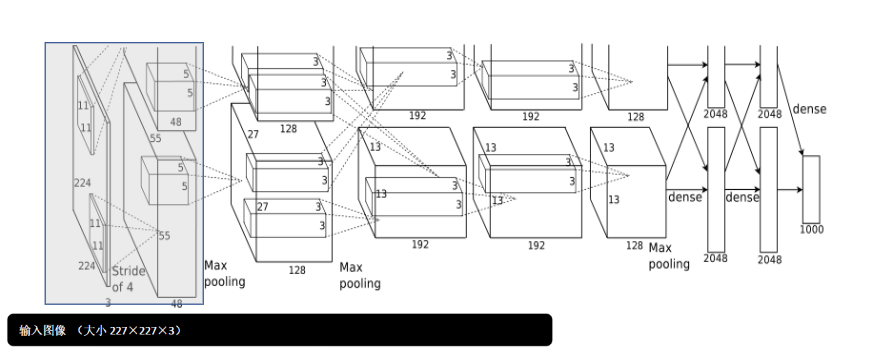
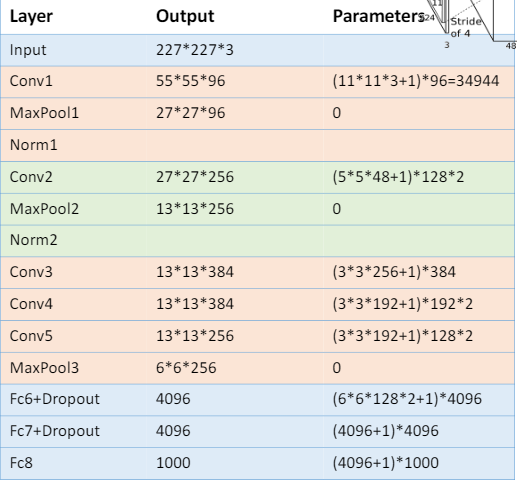
通过对经典的卷积网络模型比如LeNet的解析, 分为多个卷积层,激活层,池化层,然后是全连接层,最后通过Softmax函数将各分类标签通过概率表达出来。学会每一层的维度计算。
车牌识别中,需要事先将车牌中每个字符例如’沪’,’C’等切分出来,共形成65个分类,通过深度学习实际上最后预测的是车牌上的每个字符最大概率的预测字符,然后再拼接出来形成最终的识别结果。
1 | #定义网络 |
检测在密集人流区域中戴口罩和未戴口罩的所有人脸,同时判断该人是否佩戴口罩。
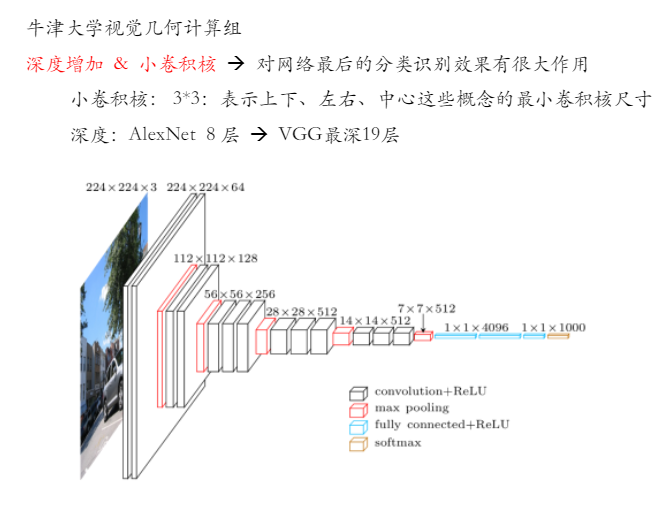
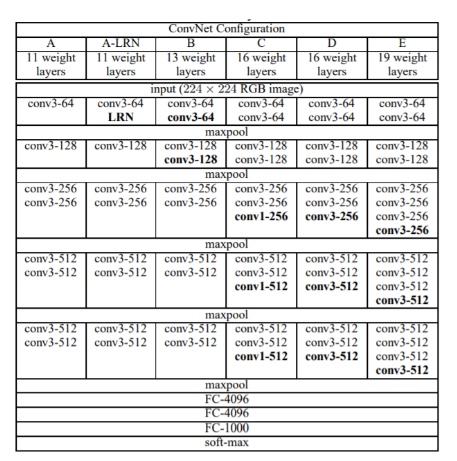
vgg模型配置
vgg网络定义:
1 | class VGGNet(fluid.dygraph.Layer): |
本竞赛所用训练和测试图片均来自一般监控场景,但包括多种视角(如低空、高空、鱼眼等),图中行人的相对尺寸也会有较大差异。部分训练数据参考了公开数据集(如ShanghaiTech [1], UCF-CC-50 [2], WorldExpo’10 [3],Mall [4] 等)。
本竞赛的数据标注均在对应json文件中,每张训练图片的标注为以下两种方式之一:
(1)部分数据对图中行人提供了方框标注(boundingbox),格式为[x, y, w, h][x,y,w,h];
(2)部分图对图中行人提供了头部的打点标注,坐标格式为[x, y][x,y]。
此外部分图片还提供了忽略区(ignore_region)标注,格式为[x_0, y_0, x_1, y_1, …, x_n, y_n]组成的多边形(注意一张图片可能有多个多边形忽略区),图片在忽略区内的部分不参与训练/测试。
人流密度检测网络训练使用的CNN模型网络配置如下:
1 |
|
通过几天的实践学习,掌握了训练的一般步骤,按照数据处理,配置网络,训练网络,模型评估和模型预测这样的步骤,再就是本地没GPU加速,运用百度paddle提供免费的算力,进行参数调优,但是对如何调整参数获得更好的效果,还是不太会。
我在安装了pycharm汉化包之后,发现pycharm点击设置setting没反应,不能打开。网上找了解决方案:
一般的问题都是装了中文汉化包resources_cn.jar造成的,解决办法:
Machine Learning(机器学习)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
有一个算法叫支持向量机,里面有个巧妙的数学技巧,能让计算机处理无限多个特征。
监督学习:其基本思想是数据集中的每个样本都有相应的“正确答案”,再根据这些样本作出预测。例如垃圾邮件问题。
无监督学习:在无监督学习中,不同于监督学习的数据的样子(每条数据都有特定的标签,标明零件是正品还是次品),即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇,无监督学习算法可能会把这些数据分成两个不同的簇,所以叫做聚类算法。例如google新闻
聚类只是无监督学习中的一种,
损失函数(代价函数),也被称作平方误差函数,用J(θ_0,θ_1)表示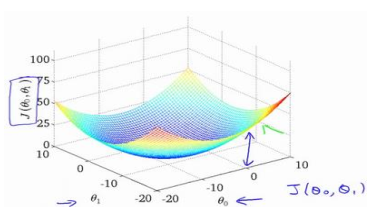
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数
J(θ_0,θ_1)的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数的组合θ_0,θ_1,………….θ_n计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
同时更新是梯度下降中的一种常用方法。
假设你将θ_1初始化在局部最低点,结果是局部最优点的导数将等于零,新的θ_1等于原来的θ_1,如果参数已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率α保持不变时,梯度下降也可以收敛到局部最低点。
 )
)

开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。




根据这个代价函数,为了拟合出参数,我们要找出让J(θ)取得最小值的参数θ

 )
)
线性回归和逻辑回归更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
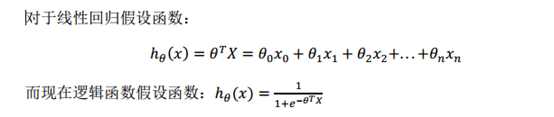
线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差,正则化技术可以改善或者减少过度拟合问题。
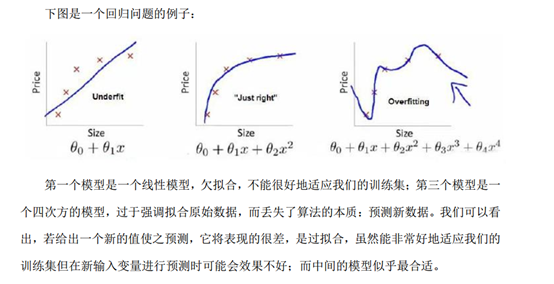
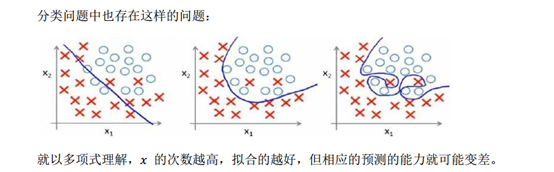
过拟合问题的处理:1.丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
2.正则化。 保留所有的特征,但是减少参数的大小(magnitude)
回归问题中我们的模型是: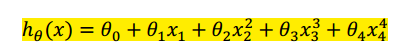
正是这些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于 0 的话,就能很好的拟合了。
我们要做的就是在一定程度上减小这些参数θ的值,这就是正则化的基本方法。
特征的直观理解:
从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的 逻辑回归中,我们被限制为使用数据中的原始特征${x_1},{x_2}, \ldots ,{x_n}$,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。
在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
为了计算代价函数的偏导数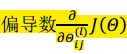 ,我们需要采用一种反向传播算法,首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。
,我们需要采用一种反向传播算法,首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。
网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多
少个单元。
第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于 1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数
越多越好。我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
在开发一个机器学习系统,或者想试着改进一个机器学习系统的性能,应该如何决定接下来应该选择哪条道路?
为了解释这一问题,我想仍然使用预测房价的学习例子,假如你已经完成了正则化线性回归,也就是最小化代价函数。一种办法是使用更多的训练样本,另一个方法是尝试选用更少的特征集。
当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么? 通常获得更多的训练实例是有效的,但代价较大。
考虑采用下面的方法:
1.尝试减少特征的数量
2.尝试获得更多的特征
3.尝试增加多项式特征
4.尝试减少正则化程度λ
5.尝试增加正则化程度λ
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。
将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来分析:
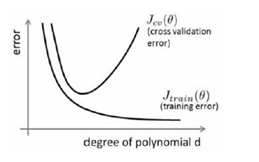
上面的曲线是交叉验证集,下面的曲线是训练集。
对于训练集,当d较小时,模型拟合程度更低,误差较大;随着d的增长,拟合程度提高,误差减小。
对于交叉验证集,当d较小时,模型拟合程度低,误差较大;但是随着d的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能
会正则化的程度太高或太小了,选择 λ 的值时也需要思考这些问题。
将训练集和交叉验证集模型的代价函数误差与 λ 的值绘制在一张图表上:

当λ较小时,训练集误差较小(过拟合)而交叉验证集误差较大;
随着λ的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后
增加。
学习曲线是一种很好的工具,可以用来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验。
学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表
适用于标签Y取值离散的情况,如1001。
梯度下降算法的每次迭代受到学习率的影响,如果学习率α过小,则达到收敛所需的迭
代次数会非常高;如果学习率α过大,每次迭代可能不会减小代价函数,可能会越过局部最
小值导致无法收敛。
泛化能力就是模型对未知数据的预测能力。在实际当中,我们通常通过测试误差来评价学习方法的泛化能力。
训练集(train set) —— 用于模型拟合的数据样本。
验证集(development set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers),或者决定反向传播算法的停止点或者在神经网络中选择隐藏层神经元的数量;
在普通的机器学习中常用的交叉验证(Cross Validation) 就是把训练数据集本身再细分成不同的验证数据集去训练模型。
测试集 —— 用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。

关于训练集、验证集、测试集的一个形象的比喻:
训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。传统上,一般三者切分的比例是:6:2:2,验证集并不是必须的
构建一个学习算法的推荐方法为:
单变量线性回归问题:
全局最小点是局部下降算法的最大点,
SVM(支持向量机)、奇异值分解。
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。

主要是拟合一条直线,使尽可能多的点落在直线上。
逻辑回归虽然名字叫做回归,但实际上却是一种分类学习方法。 线性回归完成的是回归拟合任务,而对于分类任务,我们同样需要一条线,但不是去拟合每个数据点,而是把不同类别的样本区分开来。
bagging是一种用来提高学习算法准确度的方法
https://blog.csdn.net/jiaoyangwm/article/details/79525237
决策树与随机森林都属于机器学习中监督学习的范畴,主要用于分类问题。决策树算法有这几种:ID3、C4.5、CART,基于决策树的算法有bagging、随机森林、GBDT等。决策树是一种利用树形结构进行决策的算法,对于样本数据根据已知条件或叫特征进行分叉,最终建立一棵树,树的叶子结节标识最终决策。新来的数据便可以根据这棵树进行判断。随机森林是一种通过多棵决策树进行优化决策的算法。
参考链接
SVM效果很大程度依赖kernel的设计
具体地说,线性SVM的计算部分和一个单层神经网络一样,就是一个矩阵乘积。SVM的关键在于它的Hinge Loss以及maximum margin的想法。其实这个loss也是可以用在神经网络里的(参见object detection的R-CNN方法)。对于处理非线性数据,SVM和神经网络走了两条不同的道路:神经网络通过多个隐层的方法来实现非线性的函数,有一些理论支持(比如说带隐层的神经网络可以模拟任何函数),但是目前而言还不是非常完备;SVM则采用了kernel trick的方法,这个在理论上面比较完备(RKHS,简单地说就是一个泛函的线性空间)。两者各有好坏,神经网络最近的好处是网络设计可以很灵活,但是老被人说跳大神;SVM的理论的确漂亮,但是kernel设计不是那么容易,所以最近没有那么热了。
首先要建一个Network scratch,input是28∗28的dimension,其实就是说这是一张image,image的解析度是28∗28,把它拉成长度是28∗28维的向量。output呢?现在做的是手写数字辨识,所以要决定它是0-9的哪个数字,output就是每一维对应的数字,所以output就是10维。中间假设你要两个layer,每个layer有500个hidden neuro
1 | model=Sequential() |
添加第一个hidden layer, Dense意思为添加一个全连接网络,Con2d表示添加一个convolution layer卷积层,input_dim表示输入维度,units表示hidden layer的神经元个数,activation表示激活函数,可以为relu,sigmoid,tanh,softmax,hard_sigmoid,linear等
1 | model.add(Dense(input_dim=28*28,units=500,activation='relu')) |
再添加一个layer
1 | model.add(Dense(units=500,activation='relu')) |
最后的输出层,由于是数字识别一共10个数字,所以output是10维,units=10,激活函数选择softmax
1 | model.add(Dense(units=10,activation='softmax')) |
需要定义loss function,选择optimizer,以及评估指标metrics,其实所有的optimizer都是Gradent descent based,只是有不同的方法来决定learning rate,比如Adam,SGD,RMSprop,Adagrad,Adalta,Adamax ,Nadam等,configuration完成之后就可以开始train创建的Network。
1 | model.compile(loss='categorical crossentropy',optimizer='adam',metrics=['accuracy']) |
model.fit方法,开始用Gradent Descent帮你去train你的Network,那么你要给它你的train_data input 和label,这里x_train代表image,y_train代表image的label,关于x_train和y_train的格式,你都要存成numpy array。
1 | model.fit(x_train,y_train,batch_size=100,epochs=20) |
接下来要拿train的network来使用,使用有两个不同的情景,这两个不同的情景一个是evaluation,意思就是说你的model在test data 上到底表现得怎样,call evaluate这个函数,然后把x_test,y_test喂给它,就会自动给你计算出Accuracy。它会output一个二维的向量,第一个维度代表了在test set上loss,第二个维度代表了在test set上的accuracy,这两个值是不一样的。loss可能用cross_entropy,Accuraccy是对与不对,即正确率。
1 | score = model.evaluate(x_test,y_test) |
1 | result = model.predict(x_test) |
batchsize:简单点说,就是我们一次要将多少个数据扔进模型去训练,这个值介于1和训练样本总个数之间。
iteration:迭代的次数(向模型中扔数据的次数),一个迭代= 同一批batchsize数据的一个正向通过+一个反向通过。
Epoch: 训练集中的全部样本都在训练模型中走了一遍,并返回一次(有去有回),为一个epoch。
由于这个例子中需要使用MNIST数据集,给出的源码中使用(x_train, y_train), (x_test, y_test) = mnist.load_data() 下载数据集,但是过程中需要翻墙,故我在此先将MNIST数据集的包下载下来,然后稍微修改下代码,完成数据的import.其中,numpy.load() 函数可以读取 .npy .npz 等文件类型,并返回对应的数据类型。
1)如果文件类型是 .pny 则返回一个1维数组。
2)如果文件类型是 .npz 则返回一个类似字典的数据类型,包含 {filename: array} 键值对。
1 | path = 'C:\\Users\\Administrator\\Desktop\\mnist.npz' |
下载地址:mnist数据集
提取码:gyt8
1 | import numpy as np |
添加10层,发现结果还是11%的accuracy
首先先看你在train data的performer,如果它在train data上做得好,那么可能是过拟合,如果在train data上做得不好,怎么能让它做到举一反三呢。所以至少先让它在train data 上得到好的结果。 )
)
由得到的结果发现train data acc 也是差的,就说明train没有train好,并不是overfiting过拟合。
接下来进行调参过程:
MSE均方误差不适合于分类问题,将loss function改为categorical_crossentropy,看看结果如何: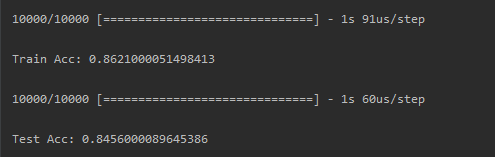
发现一换成交叉熵categorical_crossentropy,在train set上的结果就变得很好了。得到86.21%的正确率。
把sigmoid都改为relu,发现在train的accuracy就爬起来了,train的acc已经将近100分了,test 上也可以得到95.45%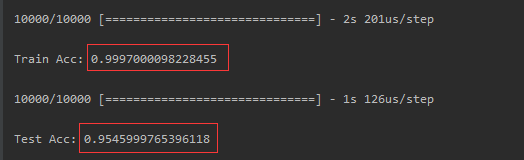
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择anaconda 3.5.2 对应的python版本是python3.6