DNN|CNN|百度paddle学习
深度学习三个步骤:
- 建立模型
- 选择什么样的网络结构
- 选择多少层,每层选择多少神经元
- 损失函数
- 选择常用损失函数,平方误差,交叉熵…..
- 参数学习
- 梯度下降
- 反向传播算法
全连接神经网络DNN由于模型结构不够灵活,模型参数太多,通过模型改进,就出现了卷积神经网络CNN。
CNN在结构上有三大特性:
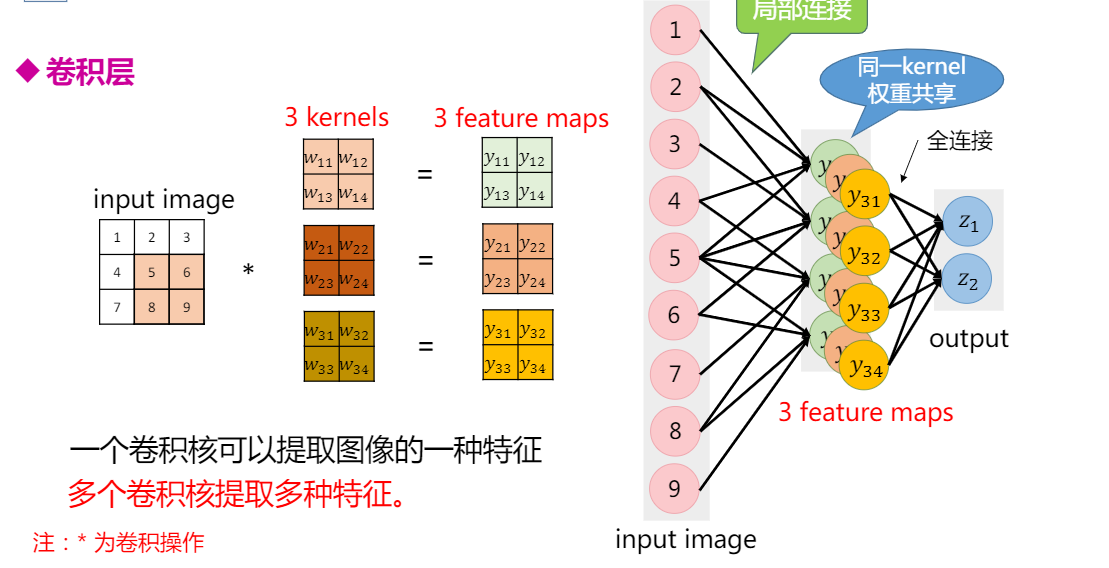
局部连接,在我们进行图像识别的时候,不需要对整个图像进行处理,只需要关注图像中某些特殊的区域,一张640x480的图片,可能其中的16x16个像素
权重共享
下采样,减小图片的尺寸,
可以减少网络参数,加快训练速度。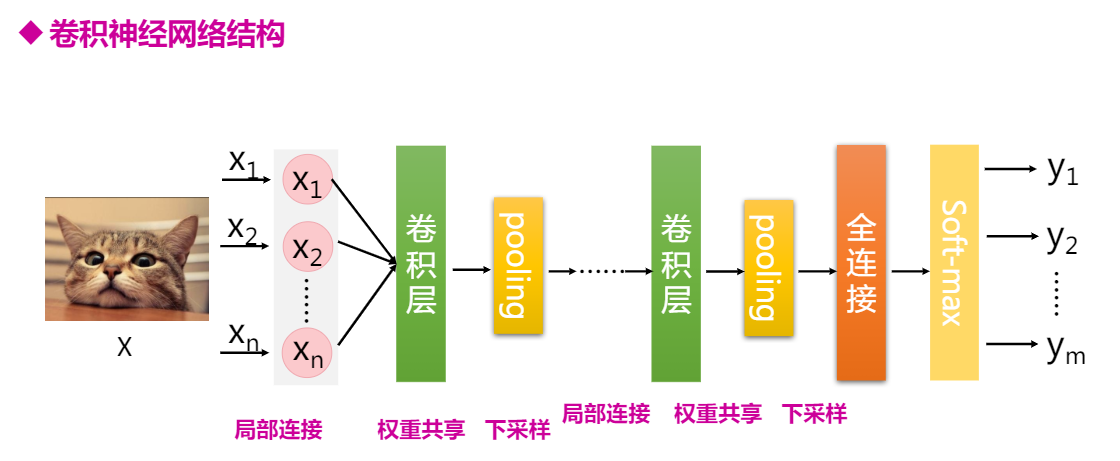 )
)
Pooling 池化层
通过下采样缩减feature map尺度。常用maxpooling和averagepooling.卷积神经网络的一般结构
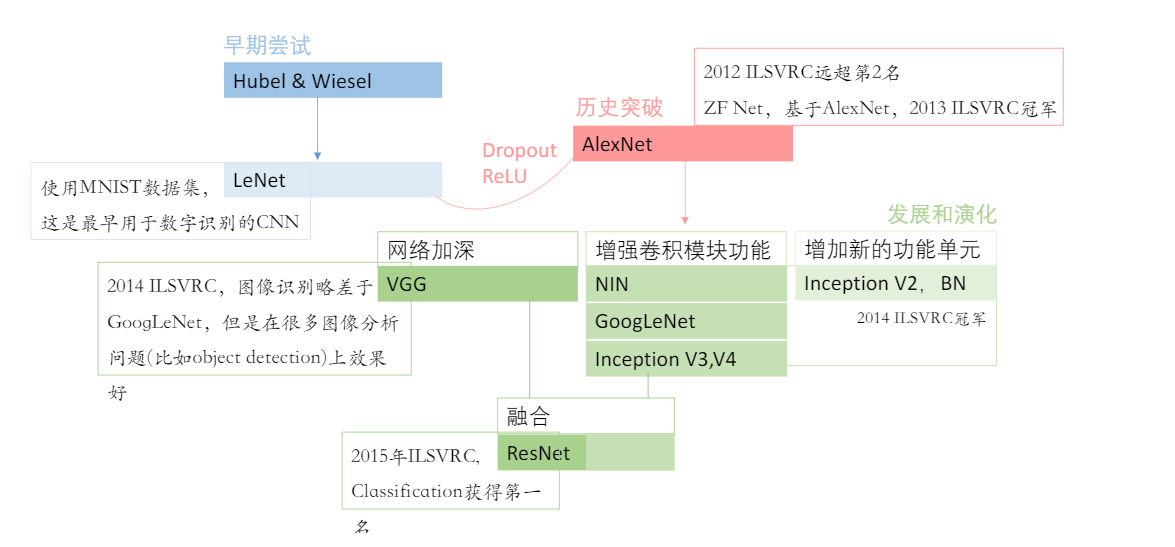
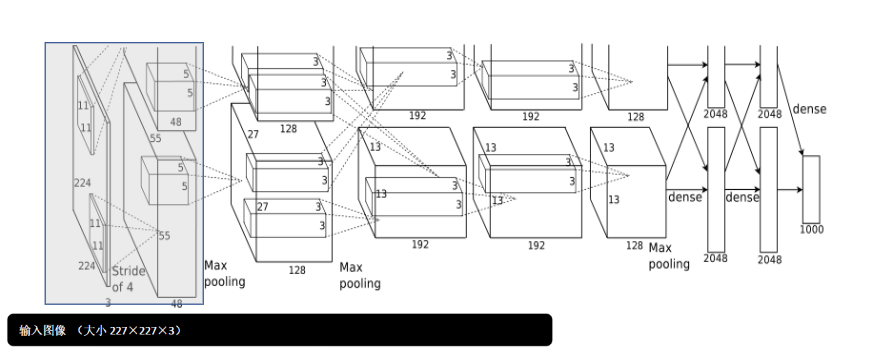
这几天参加了百度飞桨举办的深度学习7日入门-CV疫情特辑课程,通过几个疫情AI实战案例,轻松入门深度学习。
Day01 新冠疫情可视化
利用python爬取丁香园公开的统计数据,根据累计确诊数,使用pyecharts绘制疫情分布图,通过查阅Pycharts api比较容易实现
1 | import json |
结果图: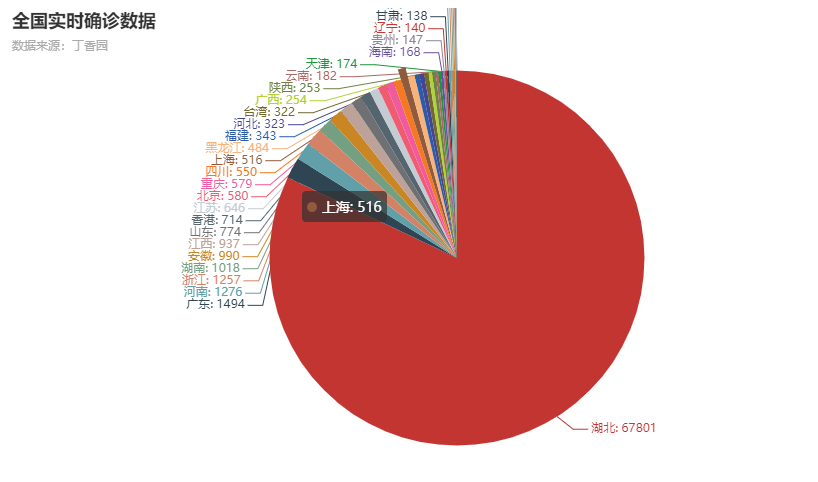
Day02手势识别
属于图像分类任务,根据图像的语义信息将不同类别图像区分开,是计算机视觉中重要的基本问题。手势识别属于图像分类中的一个细分类问题。
主要步骤:
- 准备数据
- 配置网络
- 训练网络
- 模型评估
- 模型预测
定义的DNN全连接神经网络:
1 | #定义DNN网络 |
其中通过查看Paddle API,更改了几种不同的优化器和模型参数,最终accuracy还是达不到90%,还是不太会该如何选取参数。
识别结果:
Day03-车牌识别
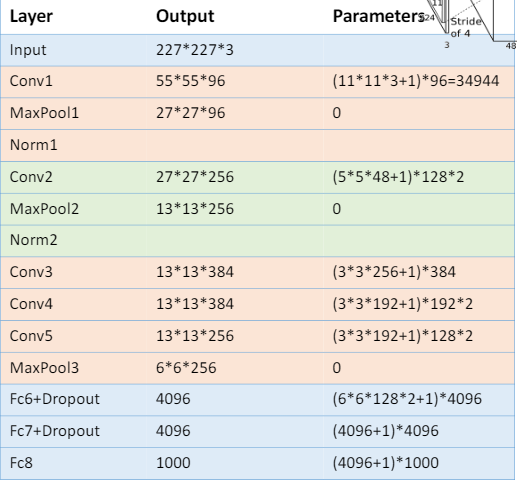
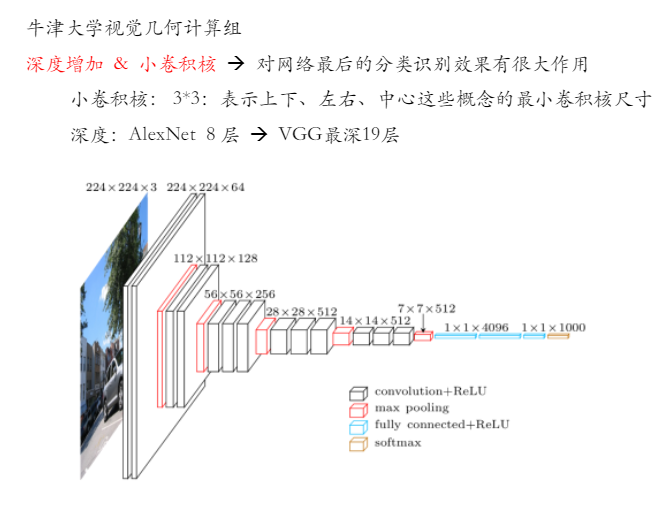
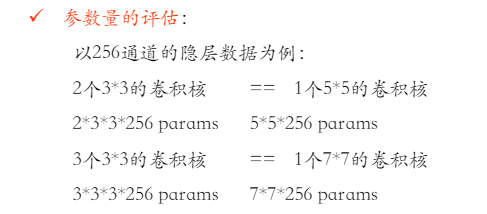
通过对经典的卷积网络模型比如LeNet的解析, 分为多个卷积层,激活层,池化层,然后是全连接层,最后通过Softmax函数将各分类标签通过概率表达出来。学会每一层的维度计算。
车牌识别中,需要事先将车牌中每个字符例如’沪’,’C’等切分出来,共形成65个分类,通过深度学习实际上最后预测的是车牌上的每个字符最大概率的预测字符,然后再拼接出来形成最终的识别结果。
1 | #定义网络 |
Day04-口罩分类
检测在密集人流区域中戴口罩和未戴口罩的所有人脸,同时判断该人是否佩戴口罩。
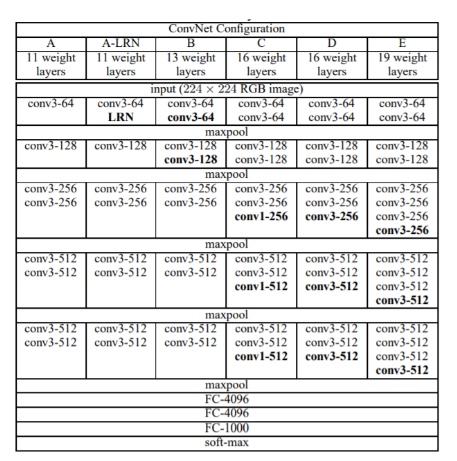
vgg模型配置
vgg网络定义:
1 | class VGGNet(fluid.dygraph.Layer): |
人流密度检测问题
本竞赛所用训练和测试图片均来自一般监控场景,但包括多种视角(如低空、高空、鱼眼等),图中行人的相对尺寸也会有较大差异。部分训练数据参考了公开数据集(如ShanghaiTech [1], UCF-CC-50 [2], WorldExpo’10 [3],Mall [4] 等)。
本竞赛的数据标注均在对应json文件中,每张训练图片的标注为以下两种方式之一:
(1)部分数据对图中行人提供了方框标注(boundingbox),格式为[x, y, w, h][x,y,w,h];
(2)部分图对图中行人提供了头部的打点标注,坐标格式为[x, y][x,y]。
此外部分图片还提供了忽略区(ignore_region)标注,格式为[x_0, y_0, x_1, y_1, …, x_n, y_n]组成的多边形(注意一张图片可能有多个多边形忽略区),图片在忽略区内的部分不参与训练/测试。
人流密度检测网络训练使用的CNN模型网络配置如下:
1 |
|
通过几天的实践学习,掌握了训练的一般步骤,按照数据处理,配置网络,训练网络,模型评估和模型预测这样的步骤,再就是本地没GPU加速,运用百度paddle提供免费的算力,进行参数调优,但是对如何调整参数获得更好的效果,还是不太会。