Kaggle-泰坦尼克号生存者预测比赛|初级入门
问题描述
- 泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。1912年4月15日,泰坦尼克号在处女航中撞上冰山沉没,2224名乘客和船员中1502人遇难。这一耸人听闻的悲剧震惊了国际社会,并导致了更好的船舶安全条例。
- 沉船造成如此巨大人员伤亡的原因之一是没有足够的救生艇来容纳乘客和船员。虽然在沉船事件中幸存下来也有一些运气的因素,但有些人比其他人更有可能幸存下来,比如妇女、儿童和上层阶级。
- 在这个挑战中,我们要求你完成对可能存活下来的人的分析。我们特别要求你们运用机器学习工具来预测哪些乘客在灾难中幸存下来。
数据来源:https://www.kaggle.com/c/titanic/data
初探数据
首先看看数据,长什么样
pandas是常用的python数据处理包,把csv文件读入称dataframe格式,数据分为两部分:训练集和测试集,训练集891行12列,测试集419行11列(无survived列)。
各列的含义如下:
|PassengerId |乘客ID编号 |
|–|–|
| Pclass | 乘客等级|
|Name | 姓名 |
|Sex | 性别 |
| Age | 年龄 |
| SibSp |堂兄弟/妹个数 |
| Parch |父母与小孩个数 |
| Ticket |船票信息 |
| Fare |票价 |
|Cabin |客舱 |
| Embarked |登船港口C,Q,S |
1.数据初步认识
1 | print(df_train.info()) |

上面的数据告诉我们训练集共有891名乘客,但是他们有些属性不全,比如:
- Age属性只有714名乘客有记录
- Cabin则只有204名乘客有记录
可以采用pandans中的describe()方法,对数据中的每一列数进行统计分析。得到数值型数据的一些分布(而有些属性比如姓名是文本型,登船港口是类目性,这些用describe()方法是看不到的)
df_train.describe()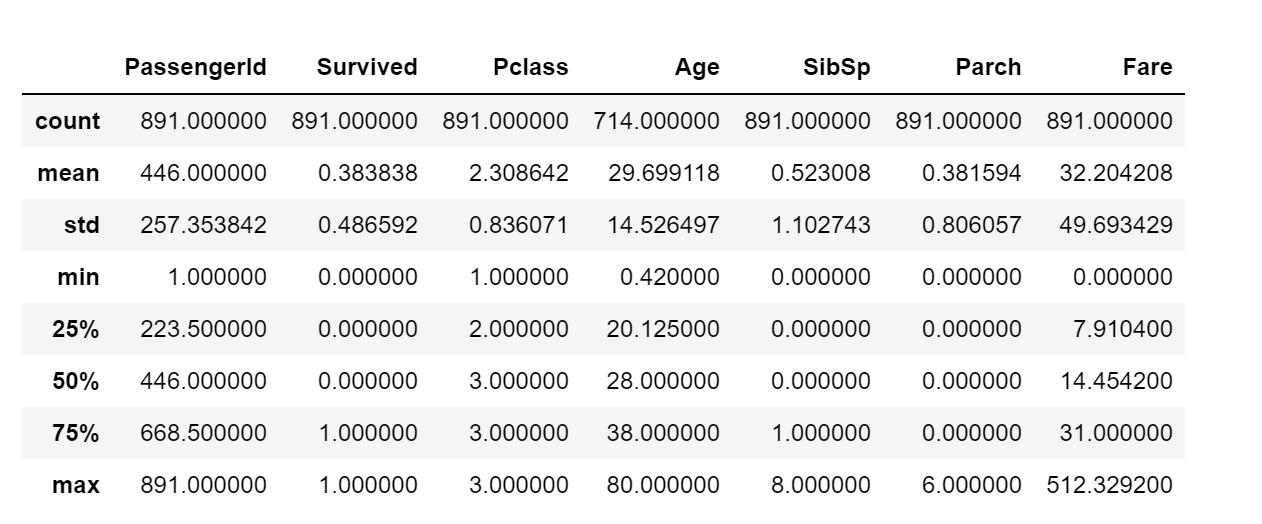
上面可以得出,大概有38.3%的人获救了,乘客的平均年龄是29.7岁。2.数据初步分析
每个乘客都有这么多属性,如何知道哪些属性更有用,又该如何使用呢。所以我们要知道,对数据的认识非常重要!看看单一/多个属性和最后的survived之间有什么样的关系。
下面使用统计学与绘图,了解数据之间的相关性,主要在以下方面: - 1.性别与幸存率的关系
- 2.乘客社会等级与幸存率的关系
- 3.配偶及兄弟姐妹数与幸存率的关系
- 4.父母及子女数与幸存率的关系
- 5.年龄与幸存率的关系
- 6.Embarked登港港口与幸存率的关系
- 7.称呼与幸存率的关系
- 8.家庭人数与幸存率的关系
- 9.不同船舱的乘客与幸存率的关系
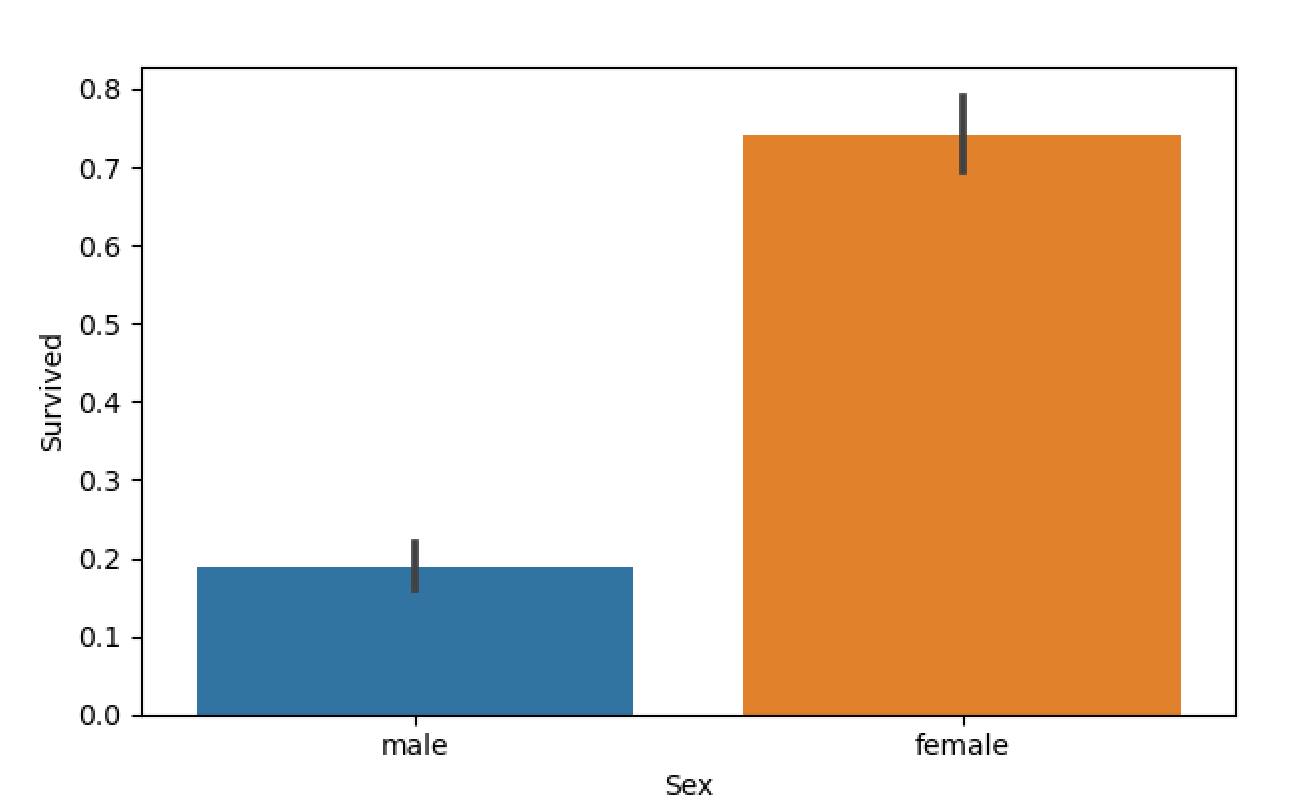
2.1性别与幸存率的关系
2.乘客社会等级与幸存率的关系
1 | sns.barplot(x='Pclass', y='Survived', data=train) |
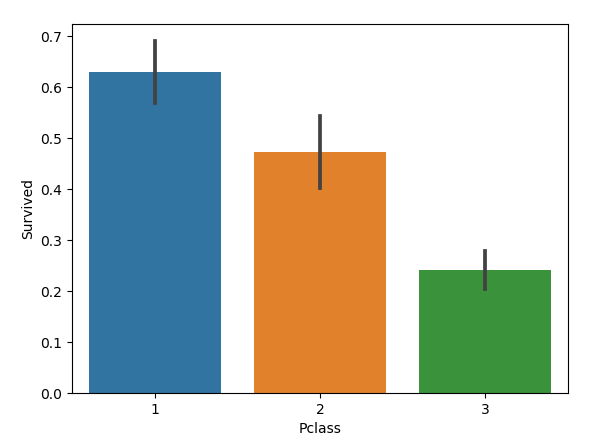
由图看出,乘客社会等级越高,幸存率越高。
3.配偶及兄弟姐妹数与幸存率的关系
1 | sns.barplot(x='SibSp', y='Survived', data=train) |
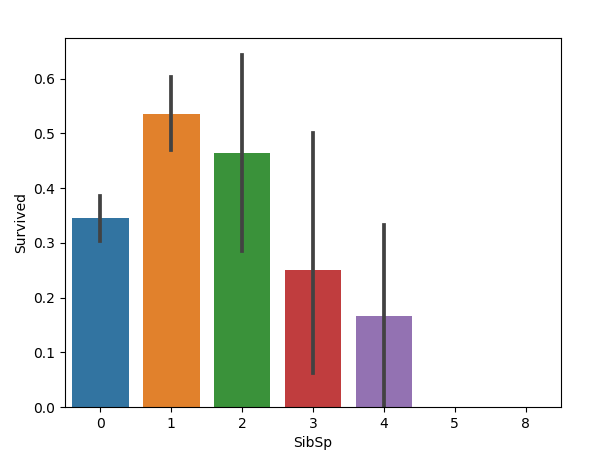
4.父母及子女数与幸存率的关系
1 | sns.barplot(x='Parch', y='Survived', data=train) |
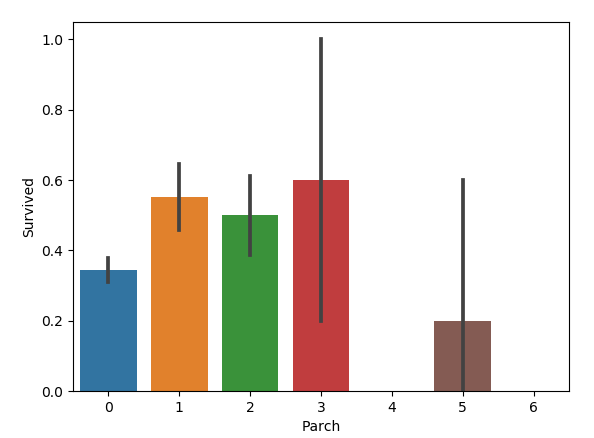
父母与子女数适中的乘客幸存率较高
5.年龄与幸存率的关系
1 | facet = sns.FacetGrid(train, hue="Survived",aspect=2) |
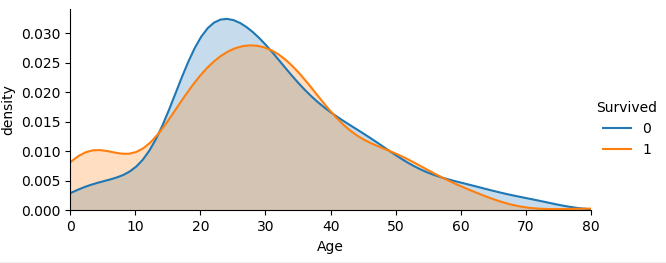
从不同生还情况的密度图可以看出,在年龄15岁的左侧,生还率有明显差别,密度图非交叉区域面积非常大,但在其他年龄段,则差别不是很明显,认为是随机所致,因此可以考虑将年龄偏小的区域分离出来。
6.Embarked登港港口与幸存率的关系
登船港口(Embarked):
- 出发地点:S = 英国南安普顿Southampton
- 途径地点1:C = 法国 瑟堡市Cherbourg
- 途径地点2:Q = 爱尔兰 昆士敦Queenstown
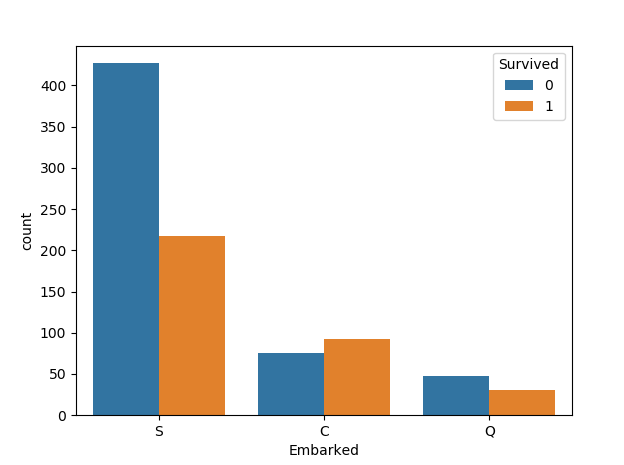
由图发现C地的生存率更高。
7.称呼与幸存率的关系
定义以下几种头衔类型,
- Officer政府官员
- Royalty王室(皇室)
- Mr已婚男士
- Mrs已婚妇女
- Miss年轻未婚女子
- Master有技能的人/教师
1
2
3
4
5
6
7
8
9
10
11
12
13all_data = pd.concat([train, test], ignore_index=True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
all_data['Title'] = all_data['Title'].map(Title_Dict)
sns.barplot(x="Title", y="Survived", data=all_data)
plt.show()
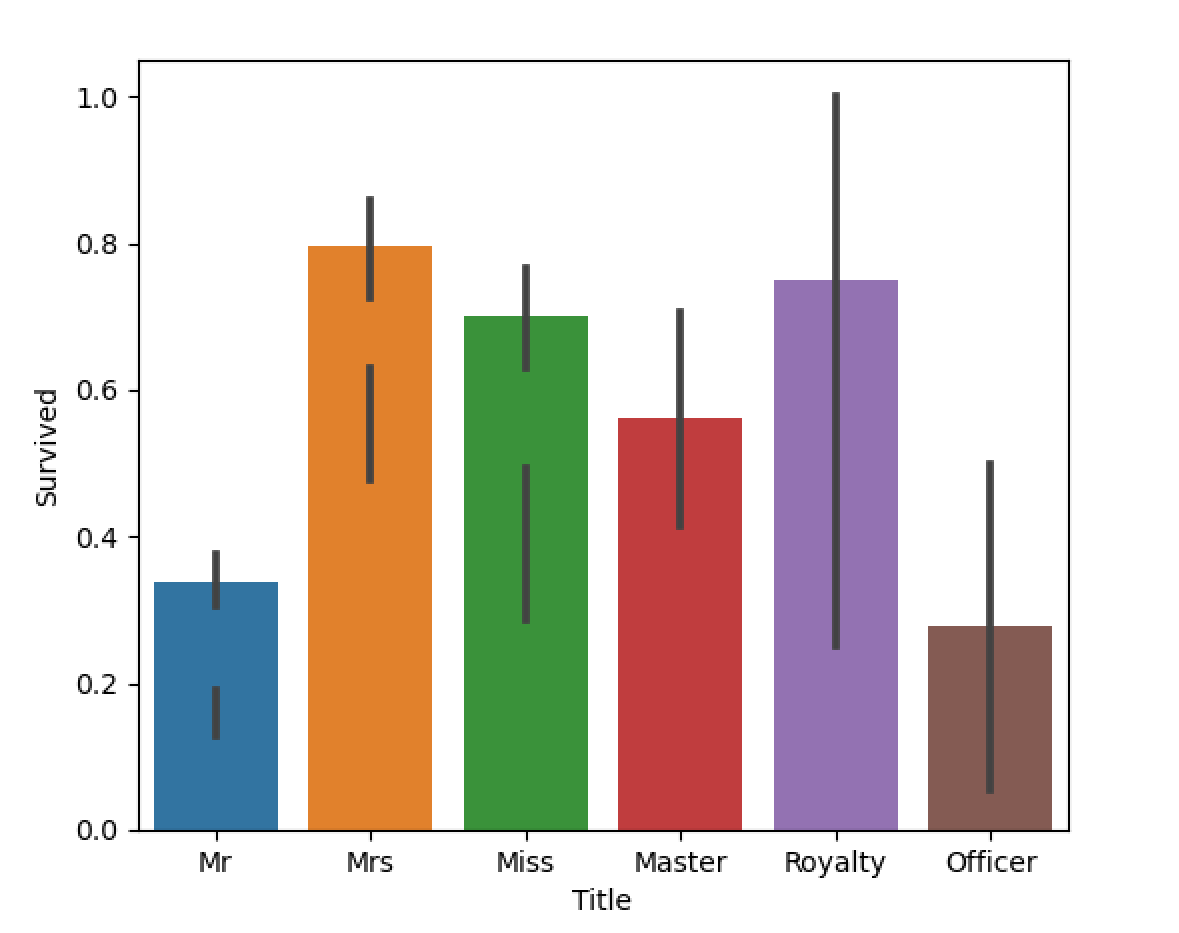
8.家庭人数与幸存率的关系
这里新增FamilyLabel特征,这个特征等于父母儿童+配偶兄弟姐妹+1,在文中就是 FamilyLabel=Parch+SibSp+1,然后将FamilySize分为三类:
1 | all_data['FamilySize']=all_data['SibSp']+all_data['Parch']+1 |
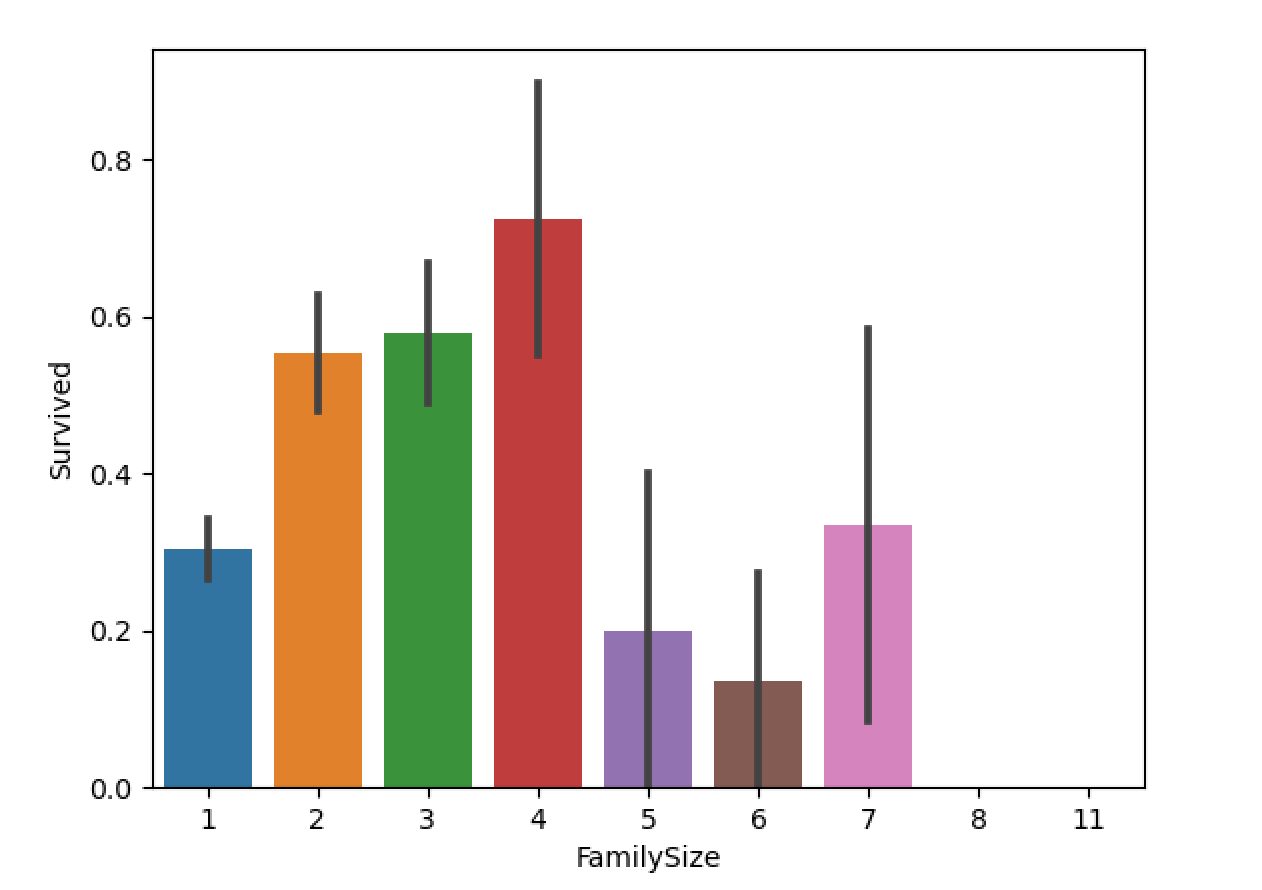
数据探索
1 | import warnings |
数据准备
1 | train.drop(['PassengerId','Name','Ticket','SibSp','Parch','Ticket','Cabin'],axis=1,inplace=True) |
模型的构建及训练
随机森林
1 | RF=RandomForestClassifier(random_state=1) |
SVC
1 | svc=make_pipeline(StandardScaler(),SVC(random_state=1)) |
完整实现代码
1 | import pandas as pd |