强化学习课程|paddle|入门
强化学习入门路线:
- 基础入门:基础概念,基本原理
- 理论补充:专业教材,高校课程
- 经典算法复现:DQN、DDPG、PPO、A3C
- 前沿论文阅读:顶会论文
什么是强化学习
简单来说就是让机器像人一样学习:
- 对已知环境进行规划
- 对未知环境进行探索/试错
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。
核心思想:智能体agent在环境environment中学习,根据环境的状态state(或观测到的observation),执行动作action,并根据环境的反馈reward(奖励)来指导更好的动作。
注意:从环境中获取的状态,有时候叫state,有时候叫observation,这两个其实一个代表全局状态,一个代表局部观测值,在多智能体环境里会有差别,但我们刚开始学习遇到的环境还没有那么复杂,可以先把这两个概念划上等号。
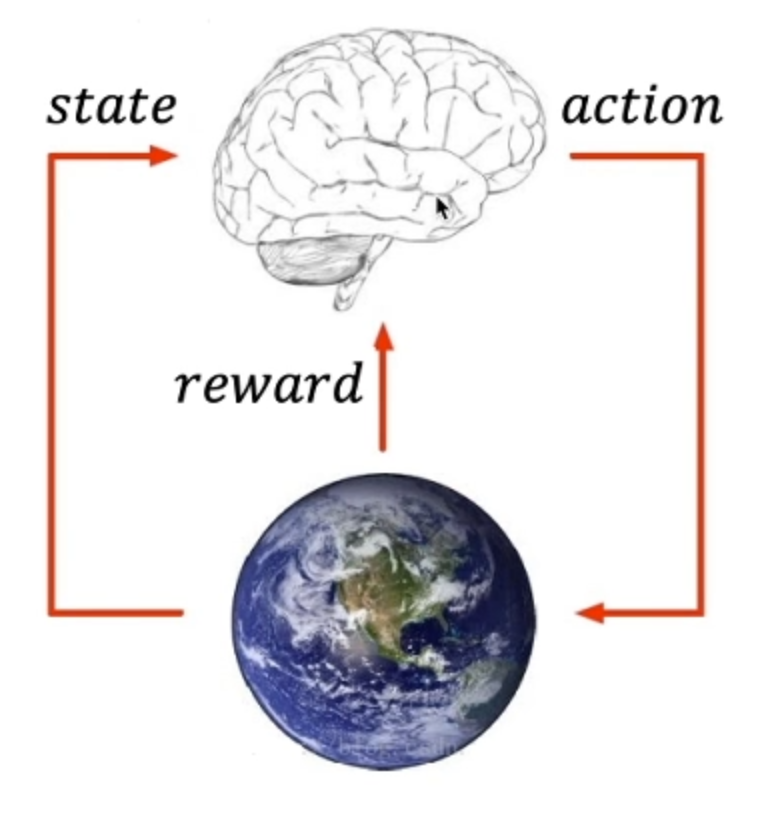
这里地球来表示environment环境,大脑表示agent,agent从environment里面去观察导state状态,然后输出action动作来去和environment做交互,会从环境中得到反馈reward来指导自己的action动作是不是正确的。
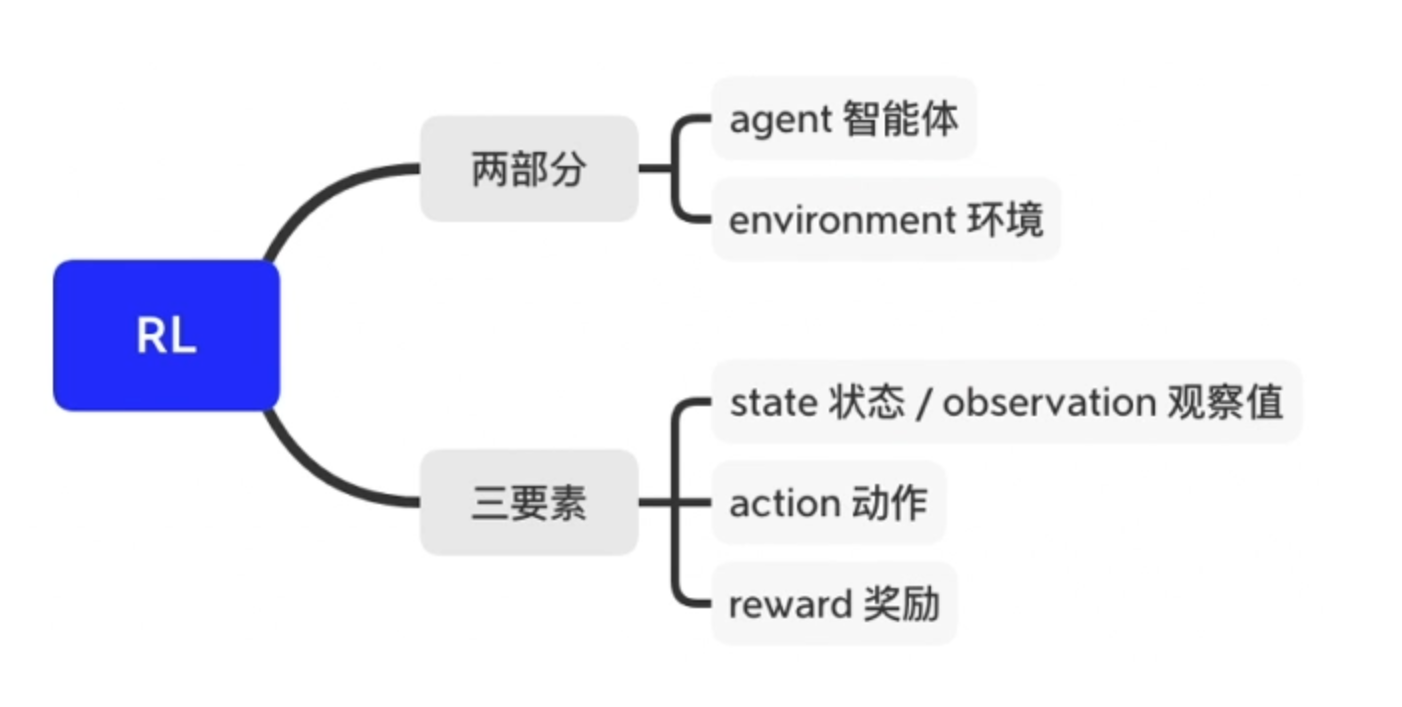
列举强化学习的一些应用
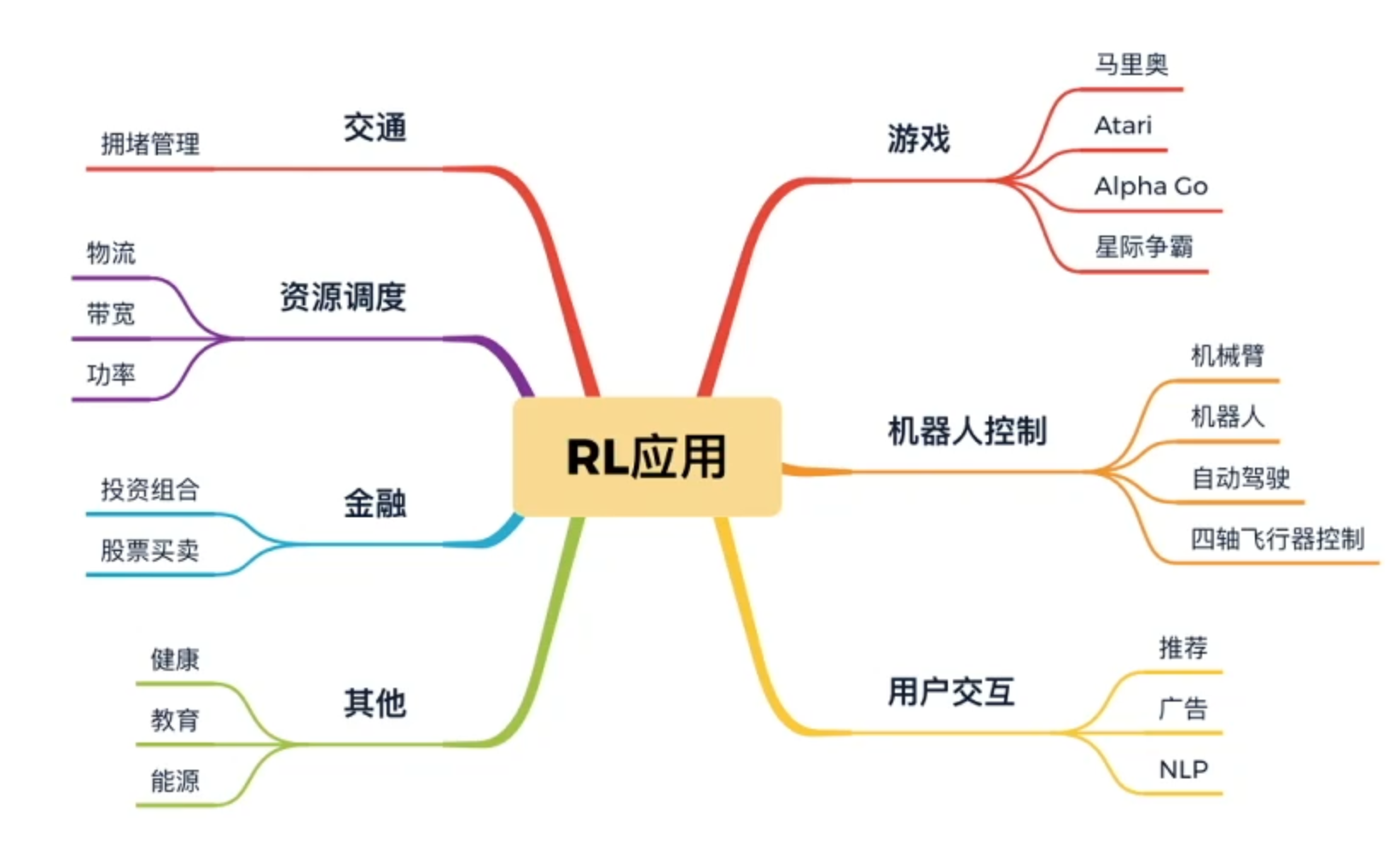
强化学习与其他机器学习的关系
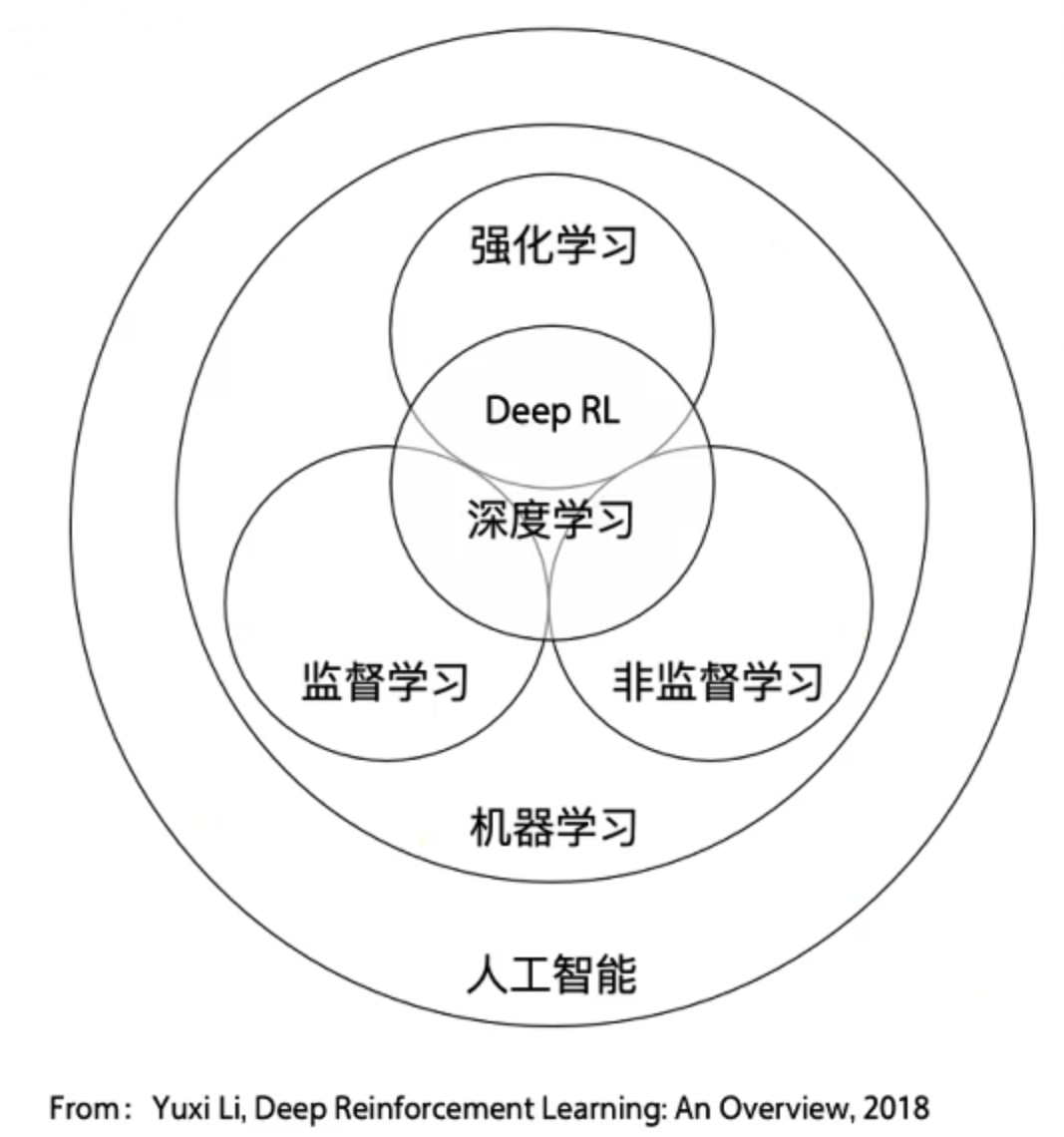
- 监督学习(分类、回归;):(认知:是什么)可理解为输入一个x,输出你想要的y。监督学习的训练数据一般样本和样本之间是独立同分布的,
- 非监督学习(聚类):输入一批x,需要分辨这个x和那个x不一样,
- 强化学习(决策:怎么做):输入的是环境的state,输出是action跟环境去交互。
上一个样本可能和下一个样本有联系,上一个样本输出的动作可能会影响下一个样本的状态。序列决策数据
强化学习的两种学习方案
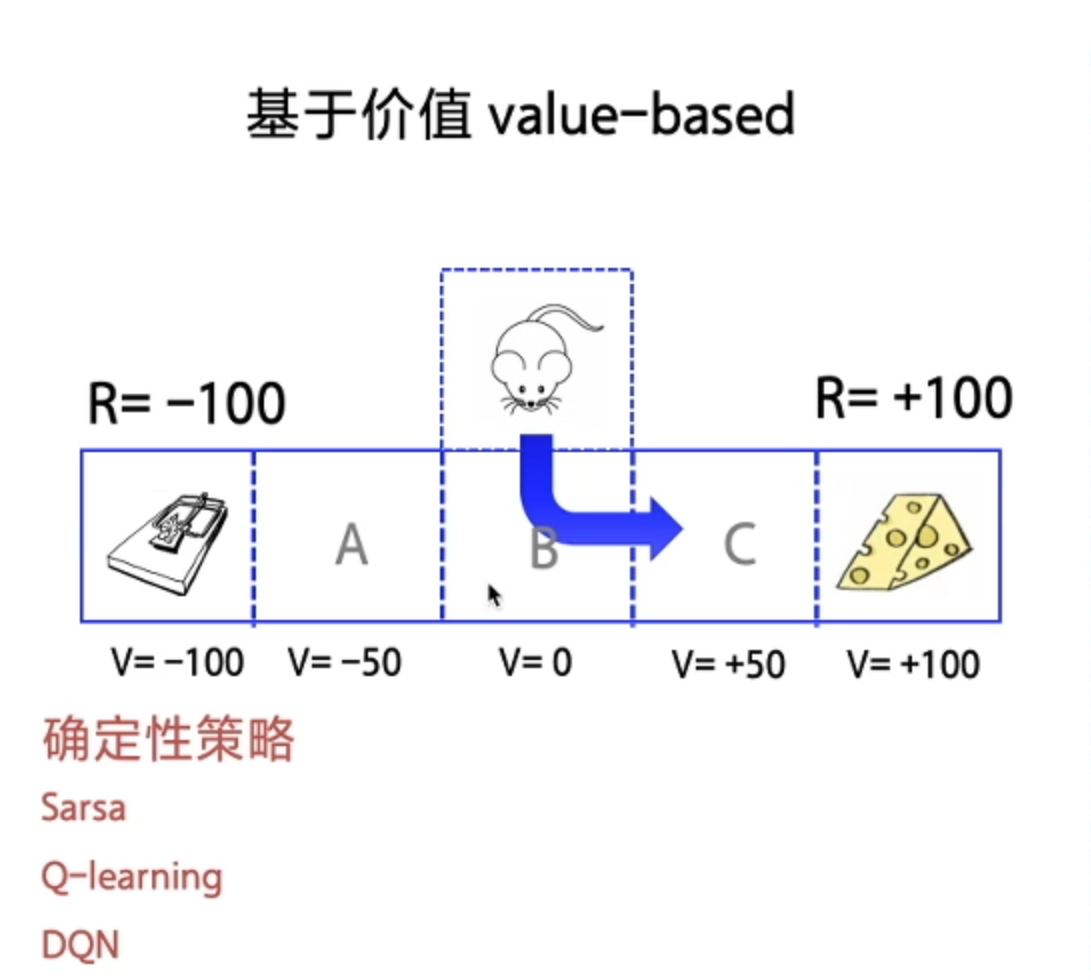
1、基于价值 Value-based (每一步 State 给奖励)—— 最终 Agent 获得每一步最优解(确定性策略)
- Sarsa
- Q-learning
- DQN
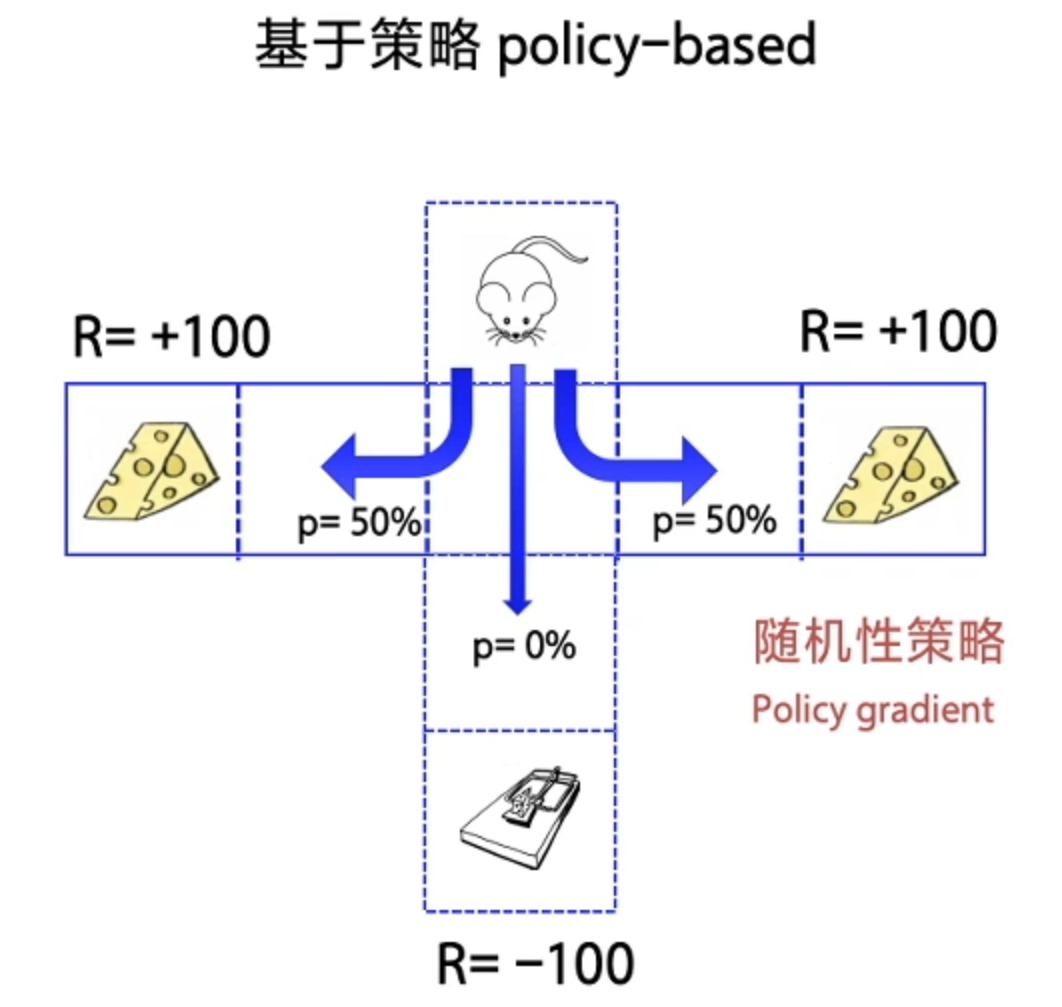
2、基于策略 Policy-based (最终给出奖励)—— 最终 Agent 获得每一步的概率分布(随机性策略) - Policy gradient
PARL实现DQN训练
1、导入依赖
1 | import parl |
2、设定一些hyperparameter超参数
1 | LEARN_FREQ = 5 # 训练频率,不需要每一个step都learn,攒一些新增经验后再learn,提高效率 |
3、搭建Model、Algorithm、Agent架构
- Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL架构可以很方便的应用在各类深度强化学习问题中。
- Agent直接跟环境来交互
- Model 是一个神经网络模型,输入State输出对于所有 action 估计的Q Values(我们会使用2个神经网络模型,一个是 Current Q Network 一个是 Target Q Network)
- Algorithm 提供Loss Function和Optimization Algorithm,接收Agent的信息,用来优化神经网络
4、Model
1 | #Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构。 |
5、Algorithm
1 | # from parl.algorithms import DQN # 也可以直接从parl库中导入DQN算法 |
6、Agent
1 | Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。 |
7、ReplayMemory
1 | # replay_memory.py |
8、Training && Test(训练&&测试)
1 | # 训练一个episode |
9、创建环境和Agent,创建经验池,启动训练,保存模型,运行代码
1 | # 创建环境 |